So far, the only type of token that can be configured from this interface is a regular expression token. Traction applies regular expression tokens at display time by scanning text tokens for sequences that match a given regular expression, and replacing all such occurrences with some other specified text. For example, one standard regular expression token that ships with Traction version 3.
Custom HTML tokens represent one of Traction's advanced customization capabilities that most administrators will not have to use, but here is a walk-through for creating your own custom HTML regular expression token.
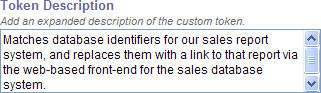
Token Description
First, we'll type a description for our token. The example we'll use here will be a token to match a key into a fictional company's sales reporting database.
This description will help other administrators understand the purpose of this token.
Regular Expression Pattern Text
Next, we'll need to author a regular expression to match our fictional sales database key strings. In our example, the database keys come in one either of the following two formats:
- 4 uppercase letters, an optional dash ("-"), and 6 digits.
- The letters "SDB", followed by an optional dash ("-"), and a 12 digit number, the first of which cannot be a 0.
Traction's regular expressions are based upon the functionality of the Java™ 2 Platform Standard Ed. 5.
\b([A-Z]{4}-?[0-9]{6}b|SDB-?[1-9][0-9]{11})\b
The \b matches word breaks, so their occurrence at the beginning and end of the pattern require that the text be its own word (i.
Replacement Text: The "Formatting String"
The formatting string is the text that Traction will substitute for character strings that match the specified regular expression pattern. In our example, suppose we want to have a link that reads "Sales Report <ID>", and links into the tracking system with a URL of the form salesdb.example.c…; (in both cases, <ID> refers to the sales report key our expression has helped us find). Our formatting string should look like this:
<A href="salesdb.example.c…}">Sales Report {1}</
The 1 that appears in curly braces ({1}) refers to the portion of the text that was matched that was captured by the pattern's first capture group. In this case, that means it refers to the sales report database key (notice that we omitted the \b line break from our capture group so that extra spaces or breaks would not be included in the portion of the expression that we need to use in the replacement text to identify the report to which we want to link). The rest of the replacement text is an HTML A tag that is rendered as a link, and the clickable text of the link.
Note: Although basic HTML is accepted in this field, many tags, such as SCRIPT, IFRAME, OBJECT, and others, may be removed for security reasons. If you have a requirement for such markup, you can manually edit the token configuration file after you have saved it. The location of the file is given near the top of the page:
After editing any token configuration file, don't forget to clear your server's caches from the General tab of the Server Setup interface. Alternatively, it is also possible to temporarily disable the security restrictions on this class of values (Setting Values). For more information on that option, see the section Transformer Configuration.
Saving and Testing the New Token
It is very important to test a new custom token configuration to make sure it's working properly. But we must first save it. We should choose a display name for the token that will help us easily identify it in the future, and then click the Save button at the bottom of the page.
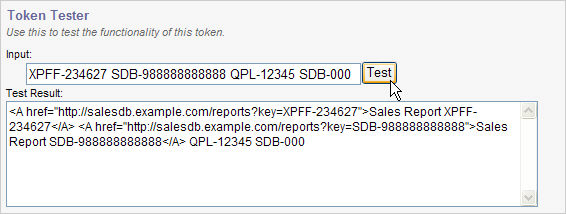
The save operation may take a moment, because adding a token configuration requires Traction to write a new token configuration file and then refresh its token configuration cache. After the operation completes, we can test our token by entering some sample text in the "Token Tester" section, and clicking the Test button. In the example here, we've used some test text that allows us to demonstrate that patterns that match exactly are replaced as expected, but other similar patterns are left intact:
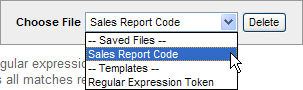
Your saved token configuration can now be reviewed or edited by returning to this Edit Token interface and selecting it (by its display name) in the token file list in the top right corner of the page:
You may configure as many regular expression tokens as your Traction deployment requires, and your replacement text can take almost any form -- including nothing at all (effectively excising that information from displayed content, though it will still be visible to anyone who can edit the article in which the pattern appears). Be careful not to construct a regular expression that matches too broad a set of strings, so that you don't replace text that isn't a genuine instance of the type of expression you're trying to match.
In the future, other types of customizable tokens (besides regular expression find-and-replace tokens) may be supported.
Attachments:
image847.jpg
image848.jpg
image891.gif
image892.gif
image894.gif
image893.gif
image849.jpg
image850.jpg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Article: Doc53 (permalink)
Date: March 22, 2008; 3:52:40 PM Eastern Daylight Time
Author Name: Documentation Importer
Author ID: importer
Date: March 22, 2008; 3:52:40 PM Eastern Daylight Time
Author Name: Documentation Importer
Author ID: importer